电话实现大规模姓名匹配02
上一讲,我们讲到通过ner命名实体识别,实现信息提取。
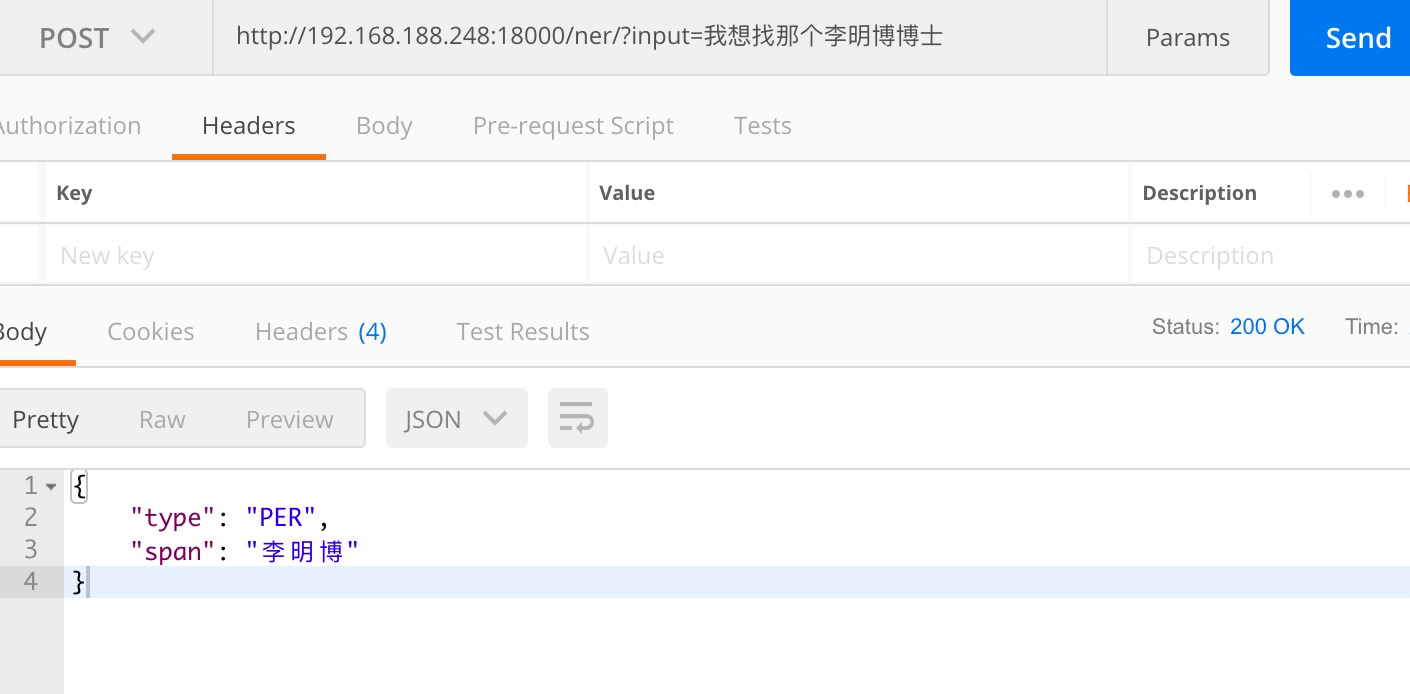
当我们分析完用户说的话,提取出对应的名称,接下来就是问题的重中之重。
如果用户说的内容asr翻译的是李命薄,或者用户不记得对方名字,只有他的昵称。鸵鸟。我们如何去解决这类问题。
多种方案
1:使用es做相似查询搜索
es及elasticsearch,熟悉es的人清楚,es将文本内容解析成token之后,使用倒排索引方式存储。
如果我们使用es进行相似匹配,效果可能不好,因为姓名此类,如何使用分词呢?按字分词检索?
2:使用词向量来做相似匹配。
我个人采用词向量方式。
什么是词向量,embedding 最近大模型爆火,很多人使用chatgpt,或者其他开源大模型时候,经常接触embedding。就是将文本转化为可以计算的向量。
词向量-可以使用对汉字的词向量,方式很多。
可以调用chatgpt的embedding接口
可以使用bert-embedding方式,甚至可以使用Word2vec等等经典方式处理。
解析出对应的embedding向量之后,将向量存储起来,形成embedding库,可以是内存,也可以其他。
然后根据用户的输入-ner结果,向量化后,计算相似度。
将输入和 embedding库进行匹配,查询出最相近的top-n,就是你要的结果。
import torch
from transformers import BertTokenizer, BertModel
from scipy.spatial.distance import cosine
# 加载BERT模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 输入文本
text1 = "I like cats"
text2 = "I love dogs"
# 文本预处理和编码
input_ids = tokenizer.encode(text1, text2, add_special_tokens=True)
input_ids = torch.tensor(input_ids).unsqueeze(0) # 添加批次维度
# 计算BERT嵌入
with torch.no_grad():
outputs = model(input_ids)
embeddings = outputs.last_hidden_state # 获取最后一层隐藏状态的输出
embeddings = torch.mean(embeddings, dim=1) # 对序列维度求平均值得到句子级别嵌入
# 计算相似度
embedding1 = embeddings[0].numpy()
embedding2 = embeddings[1].numpy()
similarity = 1 - cosine(embedding1, embedding2)
print("Similarity:", similarity)
这样就可以完成了吗?
如果你做的这一步,其他很多场景已经满足了,但是? 上述的embedding词向量方式,是基于语义的,我们的姓名等大多数是无意义场景。
解释一下,使用深度学习训练的embedding在语义方面有很强大能力,比如女子和千金,字面上是无法相似的,但是语义上是相近的。
使用深度学习的embedding在此方面很有优势,但是并不试用此类场景。
我们可以采用,拼音方式,因为很多asr翻译字不准确和口音的问题,并不会很大程度影响拼音的概率。
比如-李贵-厉鬼,ligui、ligui,在拼音上是很相似的。
我们可以使用,因此使用拼音方式,将拼音转为embedding,再计算。