word表格理解-llm
https://github.com/VikParuchuri/surya
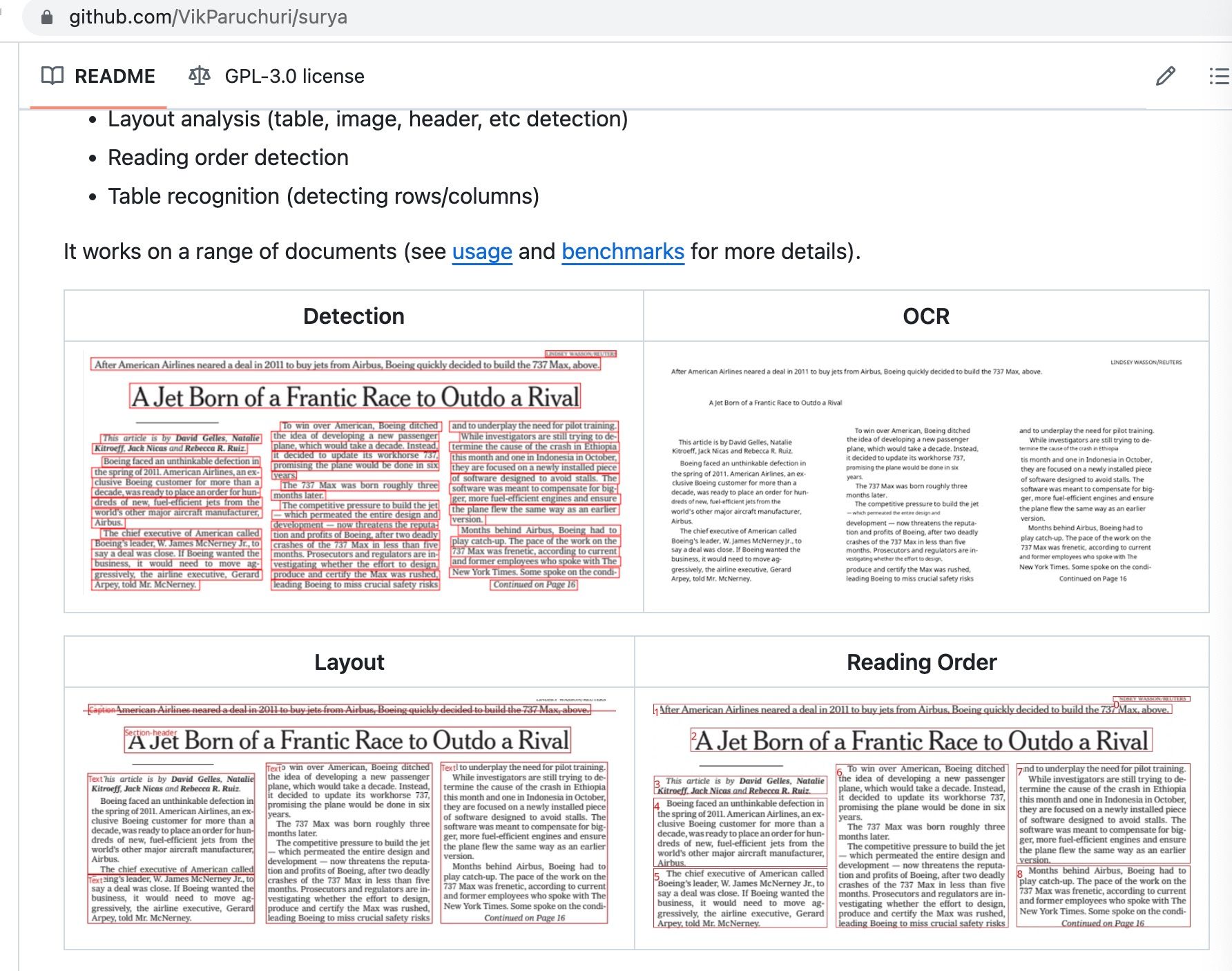
开源领域对docx表格处理的
在实现类似chatDoc ai应用时候,如果处理word的表格是一大重要业务点。
word表格识别、填充、等是对word理解的重要组成部分。
一般word理解,包含段落理解、图片理解、表格理解。
目前段落、图片理解 算是比较简单. 比较单一输入源。。
我们可以使用ocr理解图片信息、或者多模态大模型理解图片和文本。 但表格的读取理解多了一层输入。
当然我们可以直接将docx的xml所有内容扔给多模态大模型,但是资源和理解范围要求比较高,目前各类大模型均无法实现更好的效果。
我们可以跳过ocr、或者多模态处理方式,主要专注在llm对文本处理的。 我们想办法将docx中的表格,输出为html或者xml表格形式,让大模型进行处理。
我们演示:用java实现docx读取,并合并单元格等,转为同等类型html。
import java.io.FileInputStream;
import java.io.IOException;
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.List;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFTable;
import org.apache.poi.xwpf.usermodel.XWPFTableCell;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTDecimalNumber;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTTcPr;
/**
-
读取word中的表格,包括复杂表格(合并的单元格)
*/
public class TransferWordTable {/**
- 保存生成HTML时需要被忽略的单元格
*/
private ListomitCellsList = new ArrayList<>();
/**
- 生成忽略的单元格列表中的格式
- @param row
- @param col
- @return
*/
public String generateOmitCellStr(int row, int col) {
return row + ":" + col;
}
/**
- 获取当前单元格的colspan(列合并)的列数
- @param tcPr 单元格属性
- @return
*/
public int getColspan(CTTcPr tcPr) {
// 判断是否存在列合并
CTDecimalNumber gridSpan = null;
if ((gridSpan = tcPr.getGridSpan()) != null) { // 合并的起始列
// 获取合并的列数
BigInteger num = gridSpan.getVal();
return num.intValue();
} else { // 其他被合并的列或正常列
return 1;
}
}
/**
-
获取当前单元格的rowspan(行合并)的行数
-
@param table 表格
-
@param row 行值
-
@param col 列值
-
@return
*/
public int getRowspan(XWPFTable table, int row, int col) {XWPFTableCell cell = table.getRow(row).getCell(col);
// 正常独立单元格
if (!isContinueRow(cell) && !isRestartRow(cell)) {
return 1;
}
// 当前单元格的宽度
int cellWidth = getCellWidth(table, row, col);
// 当前单元格距离左侧边框的距离
int leftWidth = getLeftWidth(table, row, col);// 用户保存当前单元格行合并的单元格数-1(因为不包含自身)
Listlist = new ArrayList<>();
getRowspan(table, row, cellWidth, leftWidth, list);return list.size() + 1;
}
private void getRowspan(XWPFTable table, int row, int cellWidth, int leftWidth,
Listlist) {
// 已达到最后一行
if (row + 1 >= table.getNumberOfRows()) {
return;
}
row = row + 1;
int colsNum = table.getRow(row).getTableCells().size();
// 因为列合并单元格可能导致行合并的单元格并不在同一列,所以从头遍历列,通过属性、宽度以及距离左边框间距来判断是否是行合并
for (int i = 0; i < colsNum; i++) {
XWPFTableCell testTable = table.getRow(row).getCell(i);
// 是否为合并单元格的中间行(包括结尾行)
if (isContinueRow(testTable)) {
// 是被上一行单元格合并的单元格
if (getCellWidth(table, row, i) == cellWidth
&& getLeftWidth(table, row, i) == leftWidth) {
list.add(true);
// 被合并的单元格在生成html时需要忽略
addOmitCell(row, i);
// 去下一行继续查找
getRowspan(table, row, cellWidth, leftWidth, list);
break;
}
}
}
}/**
- 判断是否是合并行的起始行单元格
- @param tableCell
- @return
*/
public boolean isRestartRow(XWPFTableCell tableCell) {
CTTcPr tcPr = tableCell.getCTTc().getTcPr();
if (tcPr.getVMerge() == null) {
return false;
}
if (tcPr.getVMerge().getVal() == null) {
return false;
}
if (tcPr.getVMerge().getVal().toString().equalsIgnoreCase("restart")) {
return true;
}
return false;
}
/**
- 判断是否是合并行的中间行单元格(包括结尾的最后一行的单元格)
- @param tableCell
- @return
*/
public boolean isContinueRow(XWPFTableCell tableCell) {
CTTcPr tcPr = tableCell.getCTTc().getTcPr();
if (tcPr.getVMerge() == null) {
return false;
}
if (tcPr.getVMerge().getVal() == null) {
return true;
}
return false;
}
public int getLeftWidth(XWPFTable table, int row, int col) {
int leftWidth = 0;
for (int i = 0; i < col; i++) {
leftWidth += getCellWidth(table, row, i);
}
return leftWidth;
}public int getCellWidth(XWPFTable table, int row, int col) {
BigInteger width = table.getRow(row).getCell(col).getCTTc().getTcPr().getTcW().getW();
return width.intValue();
}/**
- 添加忽略的单元格(被行合并的单元格,生成HTML时需要忽略)
- @param row
- @param col
*/
public void addOmitCell(int row, int col) {
String omitCellStr = generateOmitCellStr(row, col);
omitCellsList.add(omitCellStr);
}
public boolean isOmitCell(int row, int col) {
String cellStr = generateOmitCellStr(row, col);
return omitCellsList.contains(cellStr);
}public String readTable(XWPFTable table) throws IOException {
// 表格行数
int tableRowsSize = table.getRows().size();
StringBuilder tableToHtmlStr = new StringBuilder("");
for (int i = 0; i < tableRowsSize; i++) { tableToHtmlStr.append("<tr>"); int tableCellsSize = table.getRow(i).getTableCells().size(); for (int j = 0; j < tableCellsSize; j++) { if (isOmitCell(i, j)) { continue; } XWPFTableCell tableCell = table.getRow(i).getCell(j); // 获取单元格的属性 CTTcPr tcPr = tableCell.getCTTc().getTcPr(); int colspan = getColspan(tcPr); if (colspan > 1) { // 合并的列 tableToHtmlStr.append("<td colspan='" + colspan + "'"); } else { // 正常列 tableToHtmlStr.append("<td"); } int rowspan = getRowspan(table, i, j); if (rowspan > 1) { // 合并的行 tableToHtmlStr.append(" rowspan='" + rowspan + "'>"); } else { tableToHtmlStr.append(">"); } String text = tableCell.getText(); tableToHtmlStr.append(text + "</td>"); } tableToHtmlStr.append("</tr>"); } tableToHtmlStr.append("</table>"); clearTableInfo(); return tableToHtmlStr.toString();}
public void clearTableInfo() {
// System.out.println(omitCellsList);
omitCellsList.clear();
}public static void main(String[] args) {
TransferWordTable transferWordTable = new TransferWordTable();try (FileInputStream fileInputStream = new FileInputStream("E:\\下载\\table1.docx"); XWPFDocument document = new XWPFDocument(fileInputStream);) { List<XWPFTable> tables = document.getTables(); for (XWPFTable table : tables) { System.out.println(transferWordTable.readTable(table)); } } catch (IOException e) { e.printStackTrace(); }}
- 保存生成HTML时需要被忽略的单元格
}