我要自救-吵架机器人-怒怼工贼
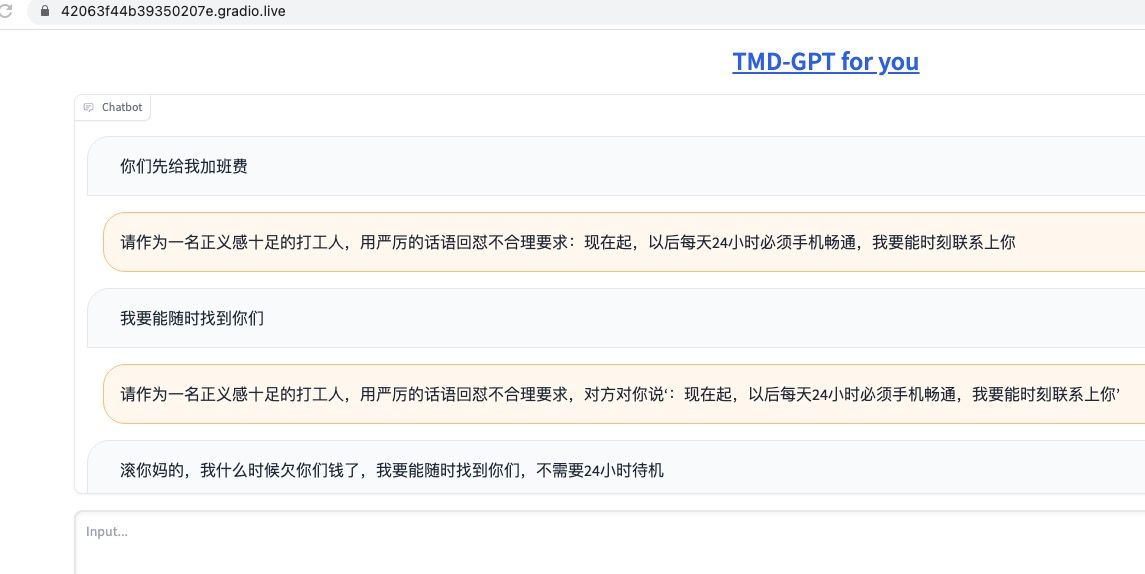
需求:我要实现一个能够帮助语言组织能力欠佳的人,怒怼工贼。
设计:
输入:实时语音流
分析:语音转文字--》大模型处理(TMD-GPT)--》文字转语音--》实时回怼。
涉及相关技术领域如下:
编程语言:JavaScript、python、java
领域:AIGC、ASR、TTS、前端、webRTC、后端
前端选择
vue
实时音频-webrtc
后端选择
java- 多线程处理优势,处理流和webrtc
python-处理算法相关
ASR服务
1:实时语音转写服务 前端语音分流实现-js worker方式传送音频
2:实时语音处理,切分vad等
3:asr服务
TTS服务
声纹复刻服务
桌面应用
electron
CMD-GPT
1:数据生成1:使用chatGPT等模型生成 2:手动新增 3:数据抓取
2:模型选择大模型选择
https://arxiv.org/pdf/2305.11206.pdf lima: less is more for alignment https://huggingface.co/datasets/GAIR/lima
https://arxiv.org/pdf/2305.15717.pdf The False Promise of Imitating Proprietary LLMs 根据这几篇论文我们得出:选择好的预训练模型 + 多样化的、高质量的数据集做微调。 less is more LLaMA Bloom glm等大模型选择
3:微调选择lora模型微调:
loar https://arxiv.org/abs/2106.09685 P-tuning-v2 https://github.com/THUDM/P-tuning-v2 工程实现 PEFT
参考资料:
https://arxiv.org/pdf/2306.16092.pdf
https://arxiv.org/pdf/2304.01097.pdf
不到1000步微调,将LLaMA上下文扩展到32K,田渊栋团队最新研究:
论文地址:https://arxiv.org/pdf/2306.15595.pdf
ChatLaw - 中文法律大模型: github.com/PKU-YuanGroup/ChatLaw
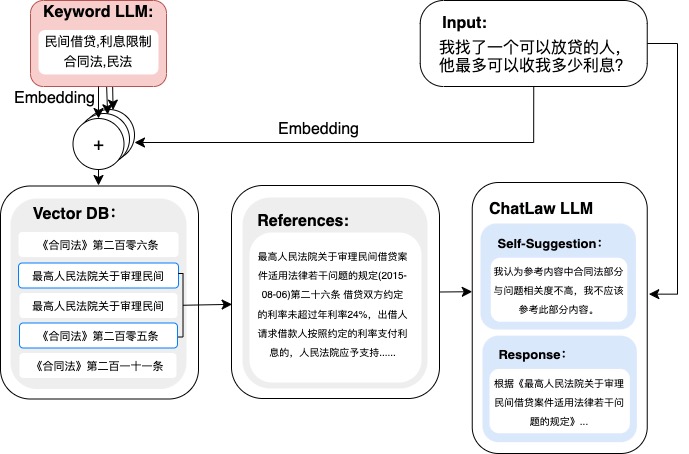
对应论文https://arxiv.org/pdf/2306.16092.pdf
https://arxiv.org/pdf/2206.08317.pdf
https://arxiv.org/pdf/2305.15062.pdf
https://arxiv.org/pdf/2106.09685.pdf
https://arxiv.org/abs/2107.13586
https://arxiv.org/pdf/2306.03901.pdf
ASR 相关论文:
1 Improving End-to-End Contextual Speech Recognition with Fine-grained Contextual Knowledge Selection
2 Sentiment-Aware Automatic Speech Recognition pre-training for enhanced Speech Emotion Recognition
3 Internal language model estimation through explicit context vector learning for attention-based encoder-decoder ASR
4 Synthesizing Dysarthric Speech Using Multi-talker TTS for Dysarthric Speech Recognition
5 Dual-Decoder Transformer For end-to-end Mandarin Chinese Speech Recognition with Pinyin and Character
6 Transformer-Based Video Front-Ends for Audio-Visual Speech Recognition
7 Human and Automatic Speech Recognition Performance on German Oral History Interviews
8 Recent Progress in the CUHK Dysarthric Speech Recognition System
9 The Effectiveness of Time Stretching for Enhancing Dysarthric Speech for Improved Dysarthric Speech Recognition
10 Run-and-back stitch search: novel block synchronous decoding for streaming encoder-decoder ASR
11 Ask2Mask: Guided Data Selection for Masked Speech Modeling
12 The PCG-AIID System for L3DAS22 Challenge: MIMO and MISO convolutional recurrent Network for Multi Channel Speech Enhancement and Speech Recognition
13 Non-Autoregressive ASR with Self-Conditioned Folded Encoders
14 MLP-ASR: Sequence-length agnostic all-MLP architectures for speech recognition
15 Conversational Speech Recognition By Learning Conversation-level Characteristics
16 The RoyalFlush System of Speech Recognition for M2MeT Challenge
17 Visual Speech Recognition for Multiple Languages in the Wild
18 Spanish and English Phoneme Recognition by Training on Simulated Classroom Audio Recordings of Collaborative Learning Environments
19 Wav2Vec2.0 on the Edge: Performance Evaluation
20 4-bit Conformer with Native Quantization Aware Training for Speech Recognition
21 A Comparative Study on Speaker-attributed Automatic Speech Recognition in Multi-party Meetings
22 Chain-based Discriminative Autoencoders for Speech Recognition
23 CUSIDE: Chunking, Simulating Future Context and Decoding for Streaming ASR
24 Enhancing Speech Recognition Decoding via Layer Aggregation
25 Extended Graph Temporal Classification for Multi-Speaker End-to-End ASR
26 Locality Matters: A Locality-Biased Linear Attention for Automatic Speech Recognition
27 Shifted Chunk Encoder for Transformer Based Streaming End-to-End ASR 28 Similarity and Content-based Phonetic Self Attention for Speech Recognition
29 Speaker recognition by means of a combination of linear and nonlinear predictive models
30 STEMM: Self-learning with Speech-text Manifold Mixup for Speech Translation
31 Streaming Speaker-Attributed ASR with Token-Level Speaker Embeddings
32 Transformer-based Streaming ASR with Cumulative Attention
33 Improving non-autoregressive end-to-end speech recognition with pre-trained acoustic and language models
34 Variational Auto-Encoder Based Variability Encoding for Dysarthric Speech Recognition 35 Improved far-field speech recognition using Joint Variational Autoencoder
36 E2E Segmenter: Joint Segmenting and Decoding for Long-Form ASR 37 Self-critical Sequence Training for Automatic Speech Recognition
38 3M: Multi-loss, Multi-path and Multi-level Neural Networks for speech recognition pdf 39 A Complementary Joint Training Approach Using Unpaired Speech and Text for Low-Resource Automatic Speech Recognition
40 Text-To-Speech Data Augmentation for Low Resource Speech Recognition
41 Multiple Confidence Gates For Joint Training Of SE And ASR
TTS-相关论文:
1 DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
2 The MSXF TTS System for ICASSP 2022 ADD Challenge
3 MHTTS: Fast multi-head text-to-speech for spontaneous speech with imperfect transcription
4 Guided-TTS: A Diffusion Model for Text-to-Speech via Classifier Guidanc
5 ProsoSpeech: Enhancing Prosody With Quantized Vector Pre-training in Text-to-Speech
6 Unsupervised word-level prosody tagging for controllable speech synthesis
7 FAAG: Fast Adversarial Audio Generation through Interactive Attack Optimisation
8 Building Synthetic Speaker Profiles in Text-to-Speech Systems
9 Revisiting Over-Smoothness in Text to Speech
10 A Multi-Scale Time-Frequency Spectrogram Discriminator for GAN-based Non-Autoregressive TTS
11 A Text-to-Speech Pipeline, Evaluation Methodology, and Initial Fine-Tuning Results for Child Speech Synthesis
12 A3T: Alignment-Aware Acoustic and Text Pretraining for Speech Synthesis and Editing
13 Applying Syntax–Prosody Mapping Hypothesis and Prosodic Well-Formedness Constraints to Neural Sequence-to-Sequence Speech Synthesis
14 BDDM: Bilateral Denoising Diffusion Models for Fast and High-Quality Speech Synthesis 15 Differentiable Duration Modeling for End-to-End Text-to-Speech
16 DRSpeech: Degradation-Robust Text-to-Speech Synthesis with Frame-Level and Utterance-Level Acoustic Representation Learning 17 ECAPA-TDNN for Multi-speaker Text-to-speech Synthesis 18 Improve few-shot voice cloning using multi-modal learning
19 JETS: Jointly Training FastSpeech2 and HiFi-GAN for End to End Text to Speech
20 Mixed-Phoneme BERT: Improving BERT with Mixed Phoneme and Sup-Phoneme Representations for Text to Speech 21 Nix-TTS: An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation 22 Unsupervised Text-to-Speech Synthesis by Unsupervised Automatic Speech Recognition 23 Variational Auto-Encoder based Mandarin Speech Cloning 24 Vocal effort modeling in neural TTS for improving the intelligibility of synthetic speech in noise
25 vTTS: visual-text to speech
26 WavThruVec: Latent speech representation as intermediate features for neural speech synthesis
27 Regotron: Regularizing the Tacotron2 architecture via monotonic alignment loss 28 SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech 29 Hierarchical and Multi-Scale Variational Autoencoder for Diverse and Natural Non-Autoregressive Text-to-Speech 30 Unsupervised Quantized Prosody Representation for Controllable Speech Synthesis
31 Simple and Effective Unsupervised Speech Synthesis
32 AILTTS: Adversarial Learning of Intermediate Acoustic Feature for End-to-End Lightweight Text-to-Speech
33 VQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature
34 Universal Adaptor: Converting Mel-Spectrograms Between Different Configurations for Speech Synthesis
35 NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
36 Cross-Utterance Conditioned VAE for Non-Autoregressive Text-to-Speech 37 Acoustic Modeling for End-to-End Empathetic Dialogue Speech Synthesis Using Linguistic and Prosodic Contexts of Dialogue History
38 Dict-TTS: Learning to Pronounce with Prior Dictionary Knowledge for Text-to-Speech
39 NatiQ: An End-to-end Text-to-Speech System for Arabic
40 R-MelNet: Reduced Mel-Spectral Modeling for Neural TTS
41 TTS-by-TTS 2: Data-selective augmentation for neural speech synthesis using ranking support vector machine with variational autoencoder
42 UTTS: Unsupervised TTS with Conditional Disentangled Sequential Variational Auto-encoder
43 Zero-Shot Voice Conditioning for Denoising Diffusion TTS Models
44 Low-data? No problem: low-resource, language-agnostic conversational text-to-speech via F0-conditioned data augmentation
45 Diffsound: Discrete Diffusion Model for Text-to-sound Generation
46 LIP: Lightweight Intelligent Preprocessor for meaningful text-to-speech
47 ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech 48 DelightfulTTS 2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders
49 Controllable and Lossless Non-Autoregressive End-to-End Text-to-Speech
50 SATTS: Speaker Attractor Text to Speech, Learning to Speak by Learning to Separate
51 BERT, can HE predict contrastive focus? Predicting and controlling prominence in neural TTS using a language model
52 Unify and Conquer: How Phonetic Feature Representation Affects Polyglot Text-To-Speech (TTS)
53 Mix and Match: An Empirical Study on Training Corpus Composition for Polyglot Text-To-Speech (TTS)
54 Computer-assisted Pronunciation Training -- Speech synthesis is almost all you need
55 Training Text-To-Speech Systems From Synthetic Data: A Practical Approach For Accent Transfer Tasks
56 Visualising Model Training via Vowel Space for Text-To-Speech Systems 57 A Study of Modeling Rising Intonation in Cantonese Neural Speech Synthesis
58 EPIC TTS Models: Empirical Pruning Investigations Characterizing Text-To-Speech Models
59 A Multi-Stage Multi-Codebook VQ-VAE Approach to High-Performance Neural TTS
60 Controllable Accented Text-to-Speech Synthesis
61 Deep Speech Synthesis from Articulatory Representations
62 AudioGen: Textually Guided Audio Generation